
We have been busy at work under the hood of the Netdata agent to introduce new capabilities that let you extend the “training window” used by Netdata’s native anomaly detection capabilities.
This blog post will discuss one of these improvements to help you reduce “false positives” by essentially extending the training window by using the new (beautifully named) number of models per dimension configuration parameter.
Background
One of the most important considerations of our native anomaly detection capabilities is the overhead of running the training and scoring computations required to train thousands of models (one per metric) and produce anomaly bits every second based on those trained models.
📑 Read more about our approach to machine learning or how our anomaly detection actually works.
It is in this context that most of our design and implementation decisions have been made. Unlike many tools that can rely on having your raw data in their cloud we can’t just take the kitchen sink approach (nor should we - it tends not to work that well in practice) and throw all the data at some sort of wrapper on something like Facebook Prophet.
Instead we have to be a bit more grown up about the design choices we face and the trade offs involved. Typically, this comes down to needing to think a bit more deeply about the ingredients we use and how we put them together, more and more this is becoming the most important aspect of actually using machine learning within your product.
Our journey so far in building native anomaly detection into the core of Netdata touches on aspects of this.
Training window
One very important consideration has been on the amount of data to train on at any one time. We need to be careful not to try and train on too large a chunk of data at any one time, since reading, pre-processing and then training on that data could have too noticeable an impact on CPU overhead.
On the other hand we also need to be careful not to train on too little data since this could lead to the model not being able to learn the “normal” patterns of the metric well enough to be able to detect anomalies.
So we started as simply as possible by continually training and retraining on the most recent 4 hours of metrics data by default. Users can extend this easily if they want the model to learn over a longer window but in terms of having to pick some default we thought this gave the best balance between a reasonable window of time to learn what might be considered “normal” patterns vs the overhead cost of the training step itself being as close to negligible as possible.
False positives
While we and many in the community have found the existing anomaly detection capabilities of Netdata very useful, especially in spotting sudden changes when things go wrong, there can of course still be “false positives” for behaviors or patterns that might just be somewhat rare and so not happen enough in any random 4 hour window to be considered “normal”.
For example, this could be something like common but irregular workloads (e.g. user driven) or cron jobs that maybe happen a few times a day or at irregular spaced out intervals. They still would be considered normal behavior on the system but for a model trained only on the last 4 hours where this pattern has never occurred they, of course, look anomalous.
So it has been clear from the start that we needed to in some way extend the amount of training data used while still being very careful not to impact training overhead on the system.
📑 If your are curious about some of our thinking and approaches here feel free to check out this GitHub discussion where we explored various ideas and approaches.
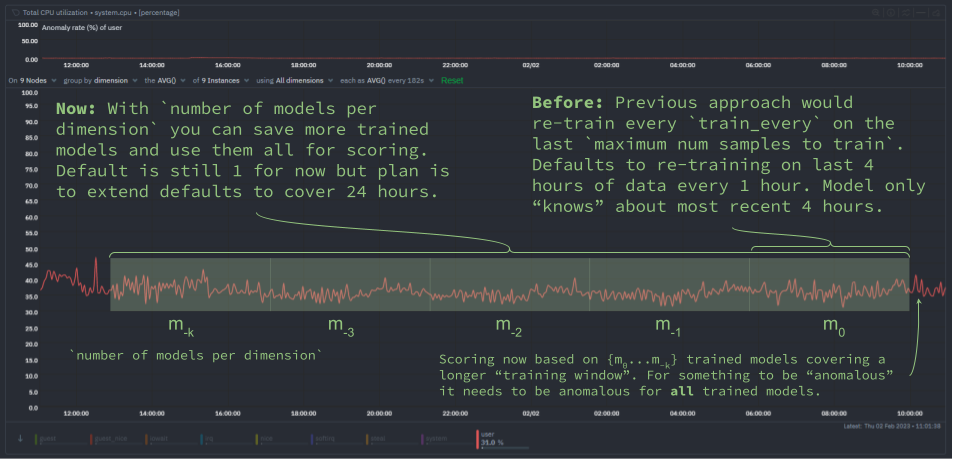
To get the best of both worlds we decided that instead of just throwing away previous models once a new one has been trained, we should hold on to them and then use them when scoring in addition to the most recently trained model.
Each trained model is essentially a compressed representation of the training data it was trained on so using more “reference” models during scoring should allow us to capture the wider range of “normal” patterns on a system really without any additional training overhead, we just need a little more space to store them (almost negligible given the kmeans models we use are just a few numbers really) and perhaps a very small performance impact during scoring (which, as we will cover below, we have also tried to be very careful about doing only when needed).
What has changed?
To this end we have introduced a new ML parameter called number of models per dimension (you can read more detail about it here) which will control the number of trained models used during scoring.
To illustrate this approach, below is some pseudo code of how the trained models are actually used in producing anomaly bits (which give you an “anomaly rate” over any window of time) each second.
# preprocess recent observations into a "feature vector"
latest_feature_vector = preprocess_data([recent_data])
# loop over each trained model
for model in models:
# if recent feature vector is considered normal by any model, stop scoring
if model.score(latest_feature_vector) < dimension_anomaly_score_threshold:
anomaly_bit = 0
break
else:
# only if all models agree the feature vector is anomalous is it considered anomalous by netdata
anomaly_bit = 1
The aim here is to only use those additional models when we need to “double check” or confirm if some potentially anomalous looking recent data should indeed be flagged as such based on a wider and more representative set of models.
So essentially once one model suggests a feature vector looks anomalous we check all saved models and only when they all agree that something is anomalous does the anomaly bit get to be finally set to 1 to signal that netdata considered the most recent feature vector unlike anything seen in all the models (spanning a wider training window) checked.
Impact on anomaly rates
Below is a typical impact of this change and the proposed new defaults mentioned below. In this set up both nodes are running the same workloads.
We can see that the overall node anomaly rate (blue line) for the ml-demo-ml-enabled-newconf node is consistent below that of the current default represented by ml-demo-ml-enabled (red line).
In the highlighted period to the right of the chart we triggered a true anomaly on both nodes. You can see both nodes “react” with an increased node anomaly rate as we would hope.

Some main takeaways here are that:
- Using more models during scoring will tend to suppress overall node anomaly rates a little.
- When anomalies are detected the overall node anomaly rate will still tend to be a little lower than before.
- When something is considered anomalous by Netdata we might have more confidence that it really is more likely to be some strange unseen pattern regardless of whether it’s actually something you need to react to or not.
- Overall this should help reduce “false positives”.
Next steps
To begin with, the default for number of models per dimension is 1 such that the new functionality collapses to the previous default of just using the single most recently trained model.
Dogfooding
The plan from here is to dogfood further internally and with the wider community while we work on two other “foundational” pieces of ML functionality:
- [Feat]: have ml work on any
update_every- ability to have anomaly detection work across all metrics regardless of theirupdate_every. This will greatly increase the coverage of ML to more metrics by default. - [Feat]: persist trained ML models to db - save the stored ML models to disk so that they are robust to agent restarts or machine reboots, currently in such cases all training needs to restart as models are stored in RAM.
Once these two features have been implemented and also dogfooded internally and by early adopters in the community we will move forward with this “update ml defaults and readme” PR to update Netdata’s ML config defaults to something like below.
The aim of the new defaults will be that roughly the last 24 hours would be trained on and so take advantage of all the foundations laid to date.
[ml]
# train on 6 hours
maximum num samples to train = 21600
# train every 3 hours
train every = 10800
number of models per dimension = 9
Try it yourself!
As of Netdata version v1.38 the new number of models per dimension parameter is available. You could try a configuration like above to see the impact it has on the anomaly rate across your infrastructure and if it helps reduce false positives within the Anomaly Advisor tab of Netdata.
We love feedback!
We’d love to hear any and all feedback you have about this feature. This is very much an initial iteration and we are hoping to continually improve the ML under the hood in the agent and the overall UX experience as users share their thoughts with us.
🚧 Note: This functionality is still under active development. We dogfood it internally and among early adopters within the Netdata community. If you would like to get involved and help us with some feedback, email us at analytics-ml-team@netdata.cloud, create a thread in the Netdata Community Forums, or come join us in the 🤖-ml-powered-monitoring channel of the Netdata discord, or open a discussion in GitHub if that’s more your thing.
Learn more
If you’d like to dive deeper and learn a little more about exactly how it all works, please feel free to check out some of the resources below.
- “How Netdata’s machine learning works” YouTube video.
- All our machine learning related blog posts.
- Anomaly Advisor documentation.
- Netdata agent ML reference documentation.
- CNCF Live session with recording on YouTube (deck).
- Anomaly Advisor playlist on the Netdata YouTube channel.
- The code itself in the Netdata Agent GitHub repo, along with a Google Collab ready notebook based Python implementation to help those interested understand how it all works under the hood, the main concepts and some illustrated explanations.
- The PR this blog post is about.
- Yet another presentation that tries to explain the main concepts and moving parts.