


IT is advancing blazingly fast. To keep up with architectural changes and hybrid environments, it’s more important than ever to maintain efficient infrastructure monitoring and troubleshooting. Adding to the complexity is the increase of distributed systems, comprised of many components and services. For IT teams to effectively manage monitoring modern infrastructure, it’s necessary to have the right practices and tools in place that enable teams to do their jobs as quickly as possible with fewer resources.
What is IT infrastructure monitoring, and why is it important?
Monitoring infrastructure is the practice of using insights to identify what’s impacting system and application performance. Gartner describes it this way: “IT infrastructure monitoring (ITIM) tools capture the health and resource utilization of IT infrastructure components that reside in a data center, the edge, infrastructure as a service (IaaS) or platform as a service (PaaS) in the cloud.”Monitoring is fundamental not only to software operations, but also to business outcomes and end goals. When relied-on systems aren’t performing their tasks, the situation can become detrimental to business operations and have an impact on customers. Practices should go beyond simply alerting IT teams when a server crashes. If set up properly, monitoring will help in proactively discovering underlying issues to shorten response time so that users never see an impact. By integrating solutions that are easily implemented and that provide robust details down to specific dimensions, infrastructure and operations leaders can dramatically improve outcomes for better performance and profitability for the business overall.
What types of IT monitoring exist?
There are many kinds of monitoring available, from application to network to SNMP, which can blur the lines between what monitoring capabilities your company needs and what solution best fits your requirements. Monitoring tools help IT teams get better visibility into events, availability, capacity, and overall health and performance. With more visibility, teams are able to get alerted when an issue occurs, troubleshoot to restore service, analyze anomaly patterns, increase reliability by reducing outages, check resource utilization, and perform root cause analysis with historical data. The graphic below breaks down the main types of monitoring.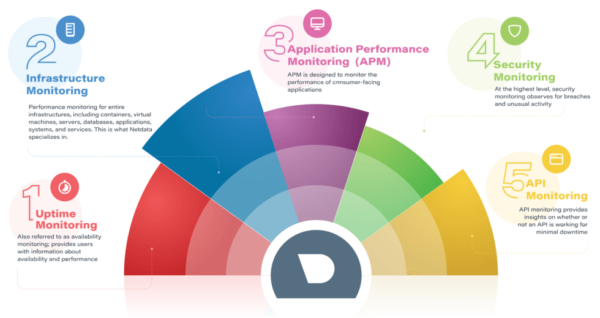
What are the challenges with current monitoring?
Often overlooked in monitoring is using real-time and historical data for troubleshooting infrastructure. Using legacy practices that focus on uptime entirely rather than adopting methods that include improving efficiency and performance will continue to widen gaps between IT and business leaders. Neglecting to find ways to optimize systems and increase agility will eventually lead to degradation of the product or service, affecting the business as a whole.An effective approach for teams will involve troubleshooting via more granular metrics beyond measuring just resource consumption like CPU or memory utilization. All metrics should be available (without resorting to the command line) and can be critical in monitoring and troubleshooting health, performance, anomalies, and outages. A more comprehensive view will help prevent constant fire-fighting by helping IT teams identify underlying issues before they result in downtime. This is the impetus behind Netdata—a troubleshooting tool that zooms into the core of the operation of systems and applications.